验证码反人类:该扔掉了!
在现代社会,但凡出点什么问题,都是靠设置屏障的手段解决。音乐盗版?防拷贝保护。网站被黑?更复杂的密码。不幸的是,这些屏障往往是给守规矩的好公民添麻烦,对坏家伙...
在现代社会,但凡出点什么问题,都是靠设置屏障的手段解决。音乐盗版?防拷贝保护。网站被黑?更复杂的密码。
不幸的是,这些屏障往往是给守规矩的好公民添麻烦,对坏家伙的拦截倒没啥用。真正的音乐盗版者、网络黑客,照样有办法绕开这些屏障。
或许这些屏障足以防范最一般的非法操作。有种名为“验证码”(验证码一词的英文叫做Captcha,即Completely Automated Public Turing Test to Tell Computers and Humans Apart的首字母缩写,意为“全自动区分计算机和人类的图灵测试”)的网络路障,其内部逻辑似乎便是如此。
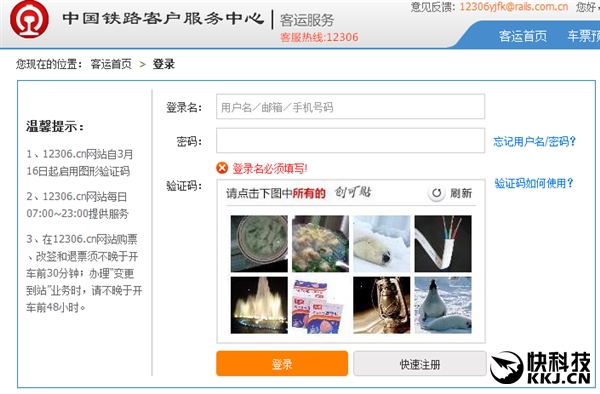
这东西你肯定见到过,就是一串常在你网上注册时出现的歪七扭八的字符——既有确实存在的英语单词,也有无实义的字母组合。你需要用键盘把你看到的字符录入到一个文本框里。
验证码出自美国卡内基梅隆大学研发人员的设计,用来防范那些可能对在线服务造成威胁的僵尸程序(一种自动执行的黑客程序)。例如有的僵尸程序会注册大量的Hotmail或雅虎邮箱账号,以便散播垃圾邮件。有的会发布一些虚假评论,企图以此提升网站在搜索结果中的排名。
理论上,只有真人才能识别出验证码图片中的字符。扭曲的字母同驳杂的背景,用人眼足以看清,计算机则不行。放行好人,拦截坏人——看起来这是一道完美的屏障。
实际上,验证码不过是以暴制暴。首先,验证码的图片常常扭曲得连人眼都认不出来。这在那些无实义的字词中体现得格外明显,就像“rl10Ozirl”。里面用的到底是小写的字母“L”还是数字“1”?是数字“0”还是字母“O”?再者,这项设计的前提是视觉能力。对失明人士而言,就无法玩儿图片验证码的游戏。
最好的验证码方案(如果这不算打自己脸的话)提供了变通的余地。例如添加一个按钮,能够让你在看不清当前图片时另换一张,还有为失明人士设计的语音验证码。
不过最重要的是,越来越多的证据表明,在这场技术大战中,验证码败象渐露。无论研究人员,还是垃圾信息散播者,都有办法绕开这道障碍。
也有网站开始尝试弃用图片验证码,改为用户体验感觉不那么糟糕的题目。做道简单的数学题,回答一个简单的问题,辨认一张照片,听段经过混音处理的音频。虽说所有这些方案还是免不了会将某个群体区隔在外——比如非英语人群或是失聪人士。
据卡内基梅隆大学的研发小组估算,全球人口每天在这些烦人的屏障入口处所耗费的时间,累计可达150000小时(17年)。
有种新型的验证码——“多重验证码”(reCaptcha),至少是把这些时间用在了公共价值的创造上。你看到的图片是一个从扫描不良的谷歌图书中截取出来的模糊单词;而你输入该词拼写的过程,其实就是在协助谷歌处理、识别一段有效文本。
即便如此,我们这些守规矩的用户,每天还是会浪费掉17年的时间。这简直是对生命的可耻浪费。一定还有其他更好的解决方案值得我们探究。
也许应该设计一款自愿出示的互联网身份证,这样一来,不管我们要注册什么,身份都是已知的。也许网站应该对每个“人”的新账号或新发表的言论施以一段时间的限制。或是监测用户的键盘输入速度或不规则程度,以此判别他们是不是人类。
或者用指纹,用视网膜扫描。诸如此类。
散播垃圾内容的僵尸程序很讨厌,这没错。可验证码同样讨厌。它极其烦人,它并非万无一失,它对所有用户搞有罪推定。
Captcha的真正含义,换个说法来说就是Computers Annoying People with Time-wasting Challenges that Howl for Alternatives——计算机那些浪费人们时间的防御机制。
是时候做出改变了。