
SQL Server Page数据库结构深入分析
SQL Server存储数据的基本单元是Page,每一个Page的大小是8KB,数据文件是由Page构成的。在同一个数据库上,每一个Page都有一个唯一的资源标识,标识符由三部分组成...
SQL Server存储数据的基本单元是Page,每一个Page的大小是8KB,数据文件是由Page构成的。在同一个数据库上,每一个Page都有一个唯一的资源标识,标识符由三部分组成:db_id,file_id,page_id,例如,15:1:8733,15是数据库的ID,1是数据文件的ID,8733是Page的编号,Page的编号从0依次递增。8个连续的Page组成一个区(Extent),数据文件中已分配(Allocated)的空间被分割成区的整数倍。一次磁盘IO操作作用于Page级别,而空间分配的最小单元是区。
Page是用于存储数据的,不同类型的Page存储的数据是不同的,Page的结构也是不同的。有些Page是用于存储数据的,叫做Data Page,有些Page是用于存储索引结构中的中间节点的,叫做Index Page,有些Page是SQL Server存储引擎使用的,用于管理Page的,叫做系统页。本文关注的是Data Page和Index Page,跟数据表有关。
日志文件没有Page结构,它是由一系列的日志记录构成的。
一,Page的结构
每一个Page都由 头部(Header),内容(Content)和行偏移量(Offset)组成,头部是在Page的开始处,占用96Bytes,用于存储Page的编号,Page的类型,分配单元(Allocation Unit)等系统信息。注:在单个Page中最多存储8060Bytes的数据。
The maximum amount of data and overhead that is contained in a single row on a page is 8,060 bytes (8 KB).
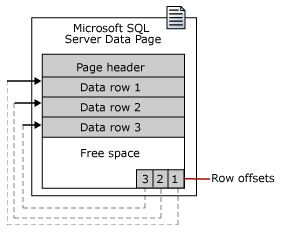
数据行存储在Page Header之后,数据行在Page中的物理存储是无序的,行的逻辑顺序是由行偏移(Row Offset)确定的,行偏移存储在Page的末尾,每一个行偏移是一个Slot,占用2B。行偏移连续排列在Page的末尾,称作槽数组(Slot Array)。行偏移以倒序方式存储行的偏移量,这意味着,从Page末尾向Page 开头计数,第一行的偏移量存储在Page的末尾Slot中,第二行的偏移量存储在Page末尾的第二个Slot中。
二,查看Page头部信息
Page头部信息存储的是Page的系统信息,可以使用非正式的命令来查看:?
DBCC PAGE(['database name'|database id], file_id, page_number, print_option = [0|1|2|3] )
参数:file_id是数据库文件的ID;page_number是Page在当前文件中的编号;print_option是指打印信息的详细程度,默认值是0,只打印Page Header。
例如,查看资源标识符:15:1:8777733 Page的头部信息:?
dbcc traceon(3604)dbcc page(15,1,8777733)
在我的数据库中,该Page的头部信息(移除Buffer的数据)如下所示,?
PAGE: (1:8777733)PAGE HEADER:Page @0x0000005188B02000m_pageId = (1:8777733) m_headerVersion = 1 m_type = 1m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x220m_objId (AllocUnitId.idObj) = 28503 m_indexId (AllocUnitId.idInd) = 256Metadata: AllocUnitId = 72057595905900544Metadata: PartitionId = 72057594059423744 Metadata: IndexId = 1Metadata: ObjectId = 1029578706 m_prevPage = (1:8777732) m_nextPage = (1:8777734)pminlen = 16 m_slotCnt = 2 m_freeCnt = 4513m_freeData = 3675 m_reservedCnt = 0 m_lsn = (1212327:16:558)m_xactReserved = 0 m_xdesId = (0:799026688) m_ghostRecCnt = 0m_tornBits = -1518328013 DB Frag ID = 1Allocation StatusGAM (1:8690944) = ALLOCATED SGAM (1:8690945) = NOT ALLOCATEDPFS (1:8775480) = 0x40 ALLOCATED 0_PCT_FULL DIFF (1:8690950) = CHANGEDML (1:8690951) = NOT MIN_LOGGED
Page 头部中各个字段的含义:
1,Page的编号
m_pageId = (1:8777733),该Page所在的File ID 和Page ID
2,Page的类型
m_type = 1,Page的类型,常见的类型是数据页和索引页:
1 – data page,用于表示:堆表或聚集索引的叶子节点
2 – index page,用于表示:聚集索引的中间节点或者非聚集索引中所有级别的节点
其他Page类型(系统页是管理Page的Page,例如,GAM,IAM等)如下:
3 – text mix page,4 – text tree page,用于存储类型为文本的大对象数据
7 – sort page,用于存储排序操作的中间数据结果
8 – GAM page,用于存储全局分配映射数据GAM(Global Allocation Map),每一个数据文件被分割成4GB的空间块(Chunk),每一个Chunk都对应一个GAM数据页,GAM数据页出现在数据文件特定的位置处,一个bit映射当前Chunk中的一个区。
9 – SGAM page,用于存储SGAM页(Shared GAM)
10 – IAM page,用于存储IAM页(Index Allocation Map)
11 – PFS page,用于存储PFS页(Page Free Space)
13 – boot page,用于存储数据库的信息,只有一个Page,Page的标识符是:db_id:1:9,
15 – file header page,存储数据文件的数据,数据库的每一个文件都有一个,Page的编号是0。
16 – diff map page,存储差异备份的映射,表示从上一次完整备份之后,该区的数据是否修改过。
17 – ML map page,表示从上一次备份之后,在大容量日志(bulk-Logged)操作期间,该区的数据是否被修改过,This is what allows you to switch to bulk-logged mode for bulk-loads and index rebuilds without worrying about breaking a backup chain.
18 – a page that's be deallocated by DBCC CHECKDB during a repair operation.
19 – the temporary page that ALTER INDEX … REORGANIZE (or DBCC INDEXDEFRAG) uses when working on an index.
20 – a page pre-allocated as part of a bulk load operation, which will eventually be formatted as a ‘real' page.
3,Page在索引中的级数
数据页在索引中的索引级数,m_level=0,表示处于Leaf Level。
对于堆表(Heap),m_level=0表示的是Data Page;
对于聚集索引,m_level=0表示的是Data Page;
对于非聚集索引,m_level=0表示的是叶子节点
4, Page的元数据
Page的元数据十分重要,不仅能够查看处Page所在的Object,甚至能够查看该Page所在的分配单元和分区ID,在死锁进行故障排除时十分有用
Metadata: AllocUnitId =72057595905900544,该Page所在的分配单元ID(allocation_unit_id)
Metadata: PartitionId =72057594059423744,该Page所在的分区的分区ID(partition_id)
Metadata: IndexId = 1,该Page所在的索引ID
Metadata: ObjectId = 1029578706,用于表示Page所属对象的object_id
5,page的链指针
由于数据表的Page并不是单独存在的,而是通过双向链式结构连接在一起的,
m_prevPage = (1:8777732) :用于表示前一个page (FileID : PageID)
m_nextPage = (1:8777734) :用于表示下一个page (FileID:PageID)
6, 其他头部字段
m_slotCnt = 2 :页面中Slot的数量,用于Page中存储的数据行数
m_freeCnt = 4513 :页面中剩余的空间,单位是字节,还剩83字节的空间
m_reservedCnt = 0 :为活动事务保留的存储空间,单位是字节
m_ghostRecCnt = 0 :页面中存在的幽灵记录的总数(ghost record count)
关于Page头部的信息,可以阅读《Inside the Storage Engine: Anatomy of a page》;
三,利用Page的元数据排除死锁
Page的元数据包含分区ID,索引ID和对象ID,用户可以使用这些元数据,分析死锁产生的原因。系统追踪到产生死锁的资源,可能是一个Page的资源标识符,如果能够确认发生死锁是由于数据表或索引的分区不合理导致的,那么可以重新设置分区列,或者设置分区边界值,把单个分区拆分成多个分区,这样就能把竞争的临界资源分配到不同的分区中,避免查询请求对资源的竞争,进而减少死锁的发生。
Metadata: PartitionId ,该Page所在的分区的分区ID(partition_id);
Metadata: IndexId ,该Page所在索引ID;
Metadata: ObjectId,用于表示对象的object_id;
原文链接:http://www.cnblogs.com/ljhdo/p/4803095.html
基于Sql server数据库的四种分页方式总结
下面小编就为大家分享一篇基于sqlserver的四种分页方式总结,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧。...
SQL Server 2016数据库快照代理过程详解
本文我们通过SQL Server 2016一个实例数据表,给大家详细分析了快照代理过程遇到的问题和解决办法,并对快照生成过程做了详细说明,以下是全部内容:...

SQL Server 全文搜索功能、全文索引方式介绍
SQL Server 的全文搜索(Full-Text Search)是基于分词的文本检索功能,依赖于全文索引。全文索引不同于传统的平衡树(B-Tree)索引和列存储索引,它是由数据表构成的,称作倒转索引(Invert Index),存储分词和行的唯一键的映射关系。...

关于SQL Serve数据库r帐号被禁用的处理方法
若发现SQL Serve所有帐号不小心被禁用了,这个时候怎么办?用重装吗?不用,仔细看小白是怎么一步一步解开这个谜题的。首先需要Windows帐号设置里重新添加一个新帐号。并将其添加到...

SQL数据库查询优化技巧提升网站访问速度的方法
在这篇文章中,我将介绍如何识别导致性能出现问题的查询,如何找出它们的问题所在,以及快速修复这些问题和其他加快查询速度的方法。 你一定知道,一个快速访问的网站能让用...

SQL数据库开发中的SSIS 延迟验证方法
验证是一个事件,该事件在Package执行时,第一个被触发,验证能够避免SSIS引擎执行一个有异常的Package或Task。延迟验证(DelayValidation)是把验证操作延迟到Package真正运行(run-ti...

SQL Server数据库建立新用户及关联数据库的方法教程
本文讲的是SQLserver数据库创建新用户方法以及赋予此用户特定权限的方法,非常的简单实用,有需要的小伙伴可以参考下...

Oracle数据库多条sql执行语句出现错误时的控制方式
多条sql执行时如果在中间的语句出现错误,后续会不会直接执行,如何进行设定,以及其他数据库诸如Mysql是如何对应的,这篇文章将会进行简单的整理和说明。环境准备使用Oracle的精简...

Oracle数据库基础:程序中调用sqlplus的方式
通过sqlplus可以连接数据库根据用户权限进行数据或者设定操作,但是需要交互操作并返回结果,这篇文章介绍一下如何在程序中使用sqlplus。环境准备使用Oracle的精简版创建docker...

oracle数据库通过sqlplus连接的几种方式介绍
分享一篇关于Oracle通过sqlplus连接数据库的方式,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧...