表分区
MySQL在5.1版引入的分区是一种简单的水平拆分,用户需要在建表的时候加上分区参数,对应用是透明的无需修改代码
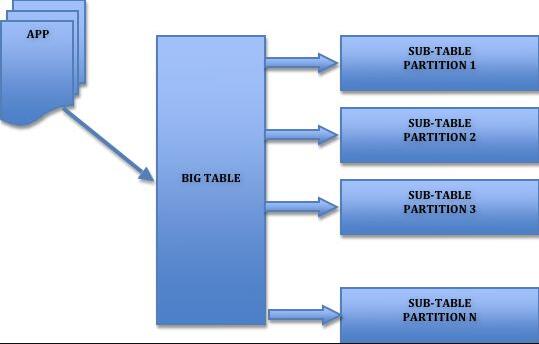
对用户来说,分区表是一个独立的逻辑表,但是底层由多个物理子表组成,实现分区的代码实际上是通过对一组底层表的对象封装,但对SQL层来说是一个完全封装底层的黑盒子。MySQL实现分区的方式也意味着索引也是按照分区的子表定义,没有全局索引。
用户的SQL语句是需要针对分区表做优化,SQL条件中要带上分区条件的列,从而使查询定位到少量的分区上,否则就会扫描全部分区,可以通过 EXPLAIN PARTITIONS来查看某条SQL语句会落在那些分区上,从而进行SQL优化,如下图5条记录落在两个分区上:
mysql> explain partitions select count(1) from user_partition where id in (1,2,3,4,5);+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+| 1 | SIMPLE | user_partition | p1,p4 | range | PRIMARY | PRIMARY | 8 | NULL | 5 | Using where; Using index |+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+1 row in set (0.00 sec)
分区的好处是:
-
可以让单表存储更多的数据
-
分区表的数据更容易维护,可以通过清楚整个分区批量删除大量数据,也可以增加新的分区来支持新插入的数据。另外,还可以对一个独立分区进行优化、检查、修复等操作
-
部分查询能够从查询条件确定只落在少数分区上,速度会很快
-
分区表的数据还可以分布在不同的物理设备上,从而搞笑利用多个硬件设备
-
可以使用分区表赖避免某些特殊瓶颈,例如InnoDB单个索引的互斥访问、ext3文件系统的inode锁竞争
-
可以备份和恢复单个分区
分区的限制和缺点:
-
一个表最多只能有1024个分区
-
如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来
-
分区表无法使用外键约束
-
NULL值会使分区过滤无效
-
所有分区必须使用相同的存储引擎
分区的类型:
-
RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区
-
LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择
-
HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL中有效的、产生非负整数值的任何表达式
-
KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值
分区适合的场景有:
最适合的场景数据的时间序列性比较强,则可以按时间来分区,如下所示:
CREATE TABLE members (firstname VARCHAR(25) NOT NULL,lastname VARCHAR(25) NOT NULL,/li>username VARCHAR(16) NOT NULL,email VARCHAR(35),joined DATE NOT NULL)PARTITION BY RANGE( YEAR(joined) ) (PARTITION p0 VALUES LESS THAN (1960),PARTITION p1 VALUES LESS THAN (1970),PARTITION p2 VALUES LESS THAN (1980),PARTITION p3 VALUES LESS THAN (1990),PARTITION p4 VALUES LESS THAN MAXVALUE);
查询时加上时间范围条件效率会非常高,同时对于不需要的历史数据能很容的批量删除。
如果数据有明显的热点,而且除了这部分数据,其他数据很少被访问到,那么可以将热点数据单独放在一个分区,让这个分区的数据能够有机会都缓存在内存中,查询时只访问一个很小的分区表,能够有效使用索引和缓存
另外MySQL有一种早期的简单的分区实现 - 合并表(merge table),限制较多且缺乏优化,不建议使用,应该用新的分区机制来替代
垂直拆分
垂直分库是根据数据库里面的数据表的相关性进行拆分,比如:一个数据库里面既存在用户数据,又存在订单数据,那么垂直拆分可以把用户数据放到用户库、把订单数据放到订单库。垂直分表是对数据表进行垂直拆分的一种方式,常见的是把一个多字段的大表按常用字段和非常用字段进行拆分,每个表里面的数据记录数一般情况下是相同的,只是字段不一样,使用主键关联
比如原始的用户表是:
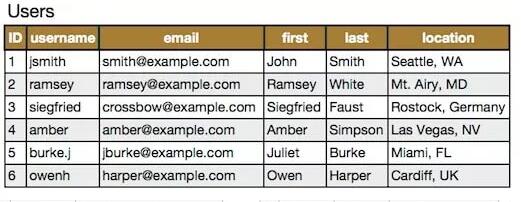
垂直拆分后是:
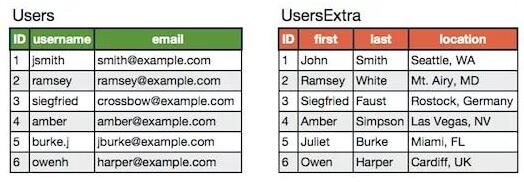
垂直拆分的优点是:
-
可以使得行数据变小,一个数据块(Block)就能存放更多的数据,在查询时就会减少I/O次数(每次查询时读取的Block 就少)
-
可以达到最大化利用Cache的目的,具体在垂直拆分的时候可以将不常变的字段放一起,将经常改变的放一起
-
数据维护简单
缺点是:
-
主键出现冗余,需要管理冗余列
-
会引起表连接JOIN操作(增加CPU开销)可以通过在业务服务器上进行join来减少数据库压力
-
依然存在单表数据量过大的问题(需要水平拆分)
-
事务处理复杂
水平拆分
概述
水平拆分是通过某种策略将数据分片来存储,分库内分表和分库两部分,每片数据会分散到不同的MySQL表或库,达到分布式的效果,能够支持非常大的数据量。前面的表分区本质上也是一种特殊的库内分表
库内分表,仅仅是单纯的解决了单一表数据过大的问题,由于没有把表的数据分布到不同的机器上,因此对于减轻MySQL服务器的压力来说,并没有太大的作用,大家还是竞争同一个物理机上的IO、CPU、网络,这个就要通过分库来解决
前面垂直拆分的用户表如果进行水平拆分,结果是:
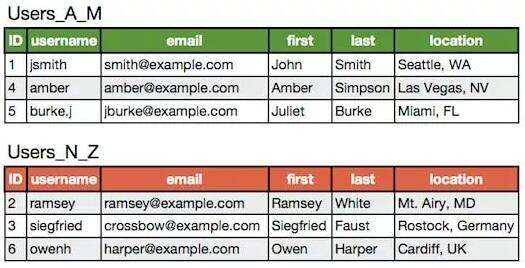
实际情况中往往会是垂直拆分和水平拆分的结合,即将 Users_A_M和 Users_N_Z再拆成 Users和 UserExtras,这样一共四张表
水平拆分的优点是:
-
不存在单库大数据和高并发的性能瓶颈
-
应用端改造较少
-
提高了系统的稳定性和负载能力
缺点是:
-
分片事务一致性难以解决
-
跨节点Join性能差,逻辑复杂
-
数据多次扩展难度跟维护量极大
分片原则
-
能不分就不分,参考单表优化
-
分片数量尽量少,分片尽量均匀分布在多个数据结点上,因为一个查询SQL跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量
-
分片规则需要慎重选择做好提前规划,分片规则的选择,需要考虑数据的增长模式,数据的访问模式,分片关联性问题,以及分片扩容问题,最近的分片策略为范围分片,枚举分片,一致性Hash分片,这几种分片都有利于扩容
-
尽量不要在一个事务中的SQL跨越多个分片,分布式事务一直是个不好处理的问题
-
查询条件尽量优化,尽量避免Select * 的方式,大量数据结果集下,会消耗大量带宽和CPU资源,查询尽量避免返回大量结果集,并且尽量为频繁使用的查询语句建立索引。
-
通过数据冗余和表分区赖降低跨库Join的可能
这里特别强调一下分片规则的选择问题,如果某个表的数据有明显的时间特征,比如订单、交易记录等,则他们通常比较合适用时间范围分片,因为具有时效性的数据,我们往往关注其近期的数据,查询条件中往往带有时间字段进行过滤,比较好的方案是,当前活跃的数据,采用跨度比较短的时间段进行分片,而历史性的数据,则采用比较长的跨度存储。
总体上来说,分片的选择是取决于最频繁的查询SQL的条件,因为不带任何Where语句的查询SQL,会遍历所有的分片,性能相对最差,因此这种SQL越多,对系统的影响越大,所以我们要尽量避免这种SQL的产生。