本文详细分析了SQL Server中表和索引结构存储的原理以及对于如何加快搜索速度和提高效率等方面做了详细的分析,以下是主要内容。
下图显示了表的存储组织,每张表有一个对应的对象ID,并且包含一个或多个分区,每个分区会有一个堆或者多个B树,堆或者B树的结构是预留的。每个堆或者是B树都有三个分配单元用来存放数据,分别是数据、LOB、行溢出,使用最多的分配单元是数据。如果有LOB数据或者是长度超过8000字节的记录,则可能有另外的LOB分配单元和行溢出分配单元。
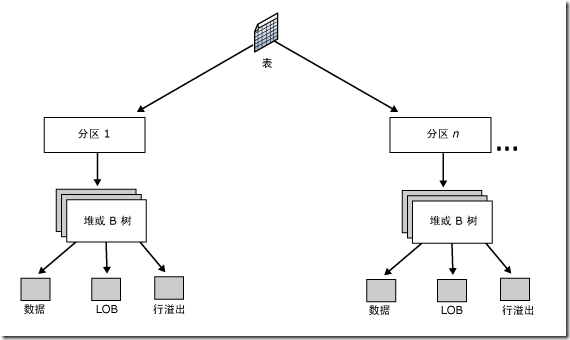
小总结: 一个表可以有多个分区,但是每个分区(堆/B树)最多有三个分配单元,每个分配单元可以有很多页,对于每个分配单元内的数据页,根据表是否有索引,以及索引是聚集还是非聚集,组织方式有以下三种:
1. 堆
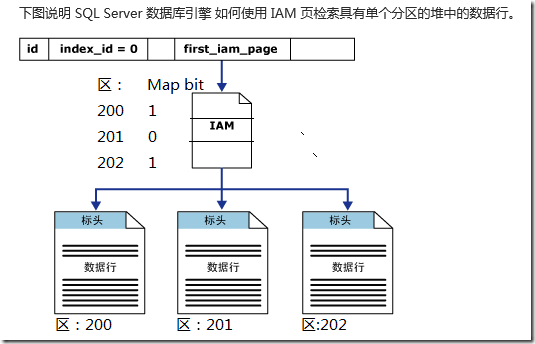
所谓堆(heap),就是不含聚集索引的表。堆的 sys.partitions 中具有一行,对于堆使用的每个分区,都有index_id= 0。只有一个分区,在系统表里,对于这个分区下面的每个分配单元都有一个连接指向Index Allocation Map页(IAM),在IAM页里,描述了区的信息。
sys.system_internals_allocation_units系统视图中的列first_iam_page指向管理特定分区中堆的分配空间的一系列 IAM 页的第一页。SQL Server 使用 IAM 页在堆中移动。堆内的数据页和行没有任何特定的顺序,也不链接在一起。数据页之间唯一的逻辑连接是记录在 IAM 页内的信息。
2. 具有非聚集索引的表
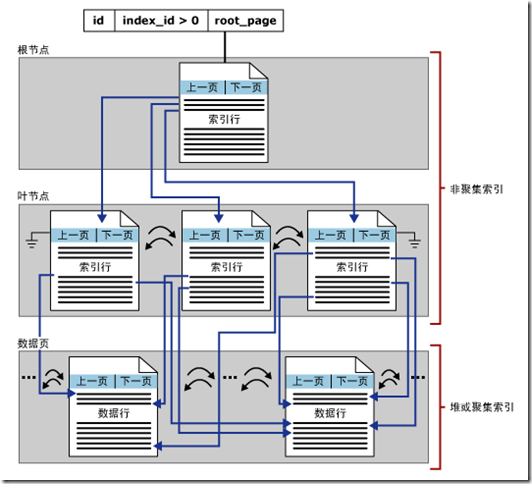
如果有一个表只有非聚集索引而没有聚集索引,对应的索引号是2--250。那么针对每个非聚集索引,都有一个对应的分区,在系统表进而,对于这个分区下面的每个分配单元,都有一个连接指向根页。数据页之间通过前后指针互相联系,是一个完整的树形结构。在树的底层,会有一个连接指向真正的数据,连接的形式是文件号+页号+行号,而真正的数据是以堆的形式存放的。如下图所示:
3. 具有聚集索引的表
表中的聚集索引,对应的索引号是1。它有一个对应的分区,该分区下的每个分配单元都有一个连接指向根页。对于聚集索引来说,叶子结点里存放的是真正的数据,而不是非聚集索引那样的连接。如下图所示:
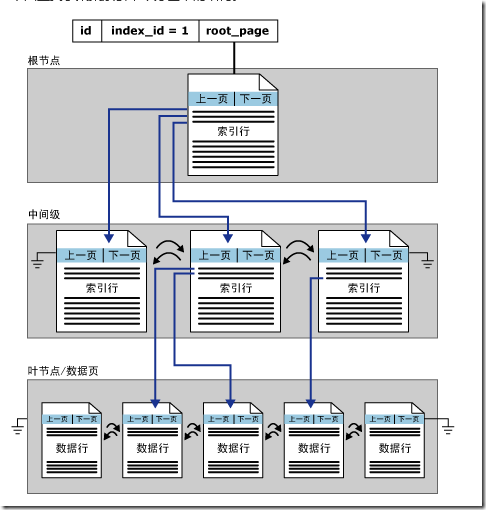
非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点:
基础表的数据行不按非聚集键的顺序排序和存储。
非聚集索引的叶层是由索引页而不是由数据页组成
案例分析: 我们来查看一个表的存储结构,我们在此使用的表是一个生产表,共有1亿多条记录,查看表的object_ID,如下图所示:

此表,我已经做了分区,查看其分区信息,可以使用下图所示的命令:
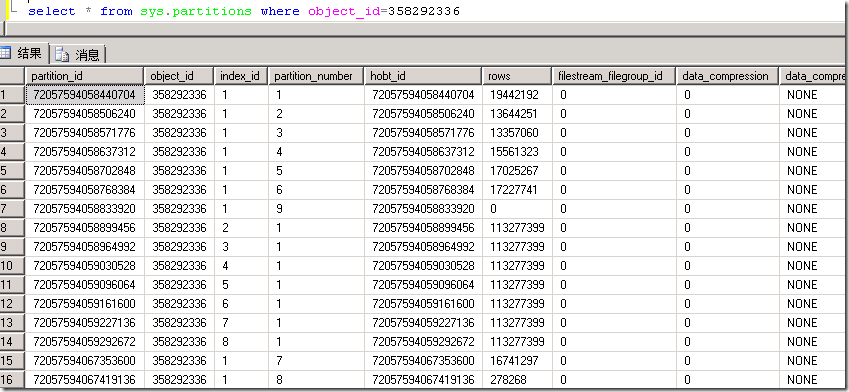
从上图可以看到,此表共有16个分区,对应不同的索引,基本上每个分区都有1千多万条记录。从此图中还可以看到堆或者B树的ID跟分区ID是一样的,如果希望进一步查看某一个索引的具体信息,可以使用下面的命令,如查看72057594067419136的信息。

从这个图当中,我们可以看到这个分区只有一个分配单元,IN_ROW_DATA表明此分配单元只用来存放具体数据,共5353页,已使用5346页,数据占用5320页。
如果希望查看根页的位置,可以使用下面的命令:

但需要注意,这里显示的根页的位置是0xEC0100001100,由于存储的关系,用倒序的方式对它进行解析,也就是0x0011000001EC,最前面的两个字节表明是所在的文件组编号,后面的4个字节是页的编号,即(1,0x01CE) ,换成十进制(1,492),然后可以利用我们上一节所说的DBCC PAGE命令查看页的信息,如下图所示:
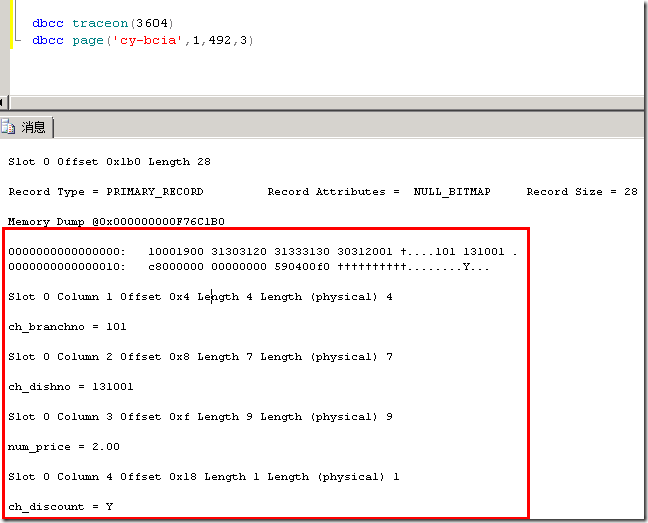
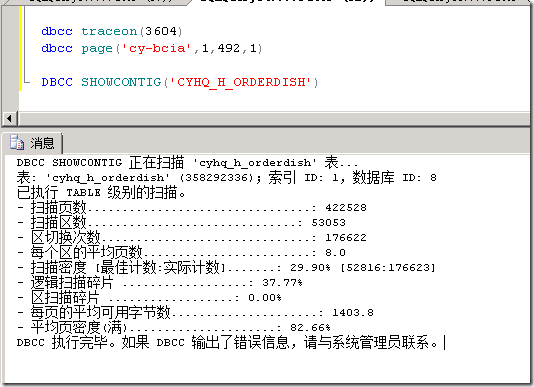
从中可以看到具体的数据,此界面的返回结果会因表上的聚集索引、非聚集索引而不同。如果查看一个表使用的总页数和区数,也可以使用命令:DBCC SHOWCONFIG,如下图所示:
在同样表结构的情况下,建立聚集索引不会增加表格的大小,但是建立非聚集索引反而会增加不少空间,在性能方面,SQL Server产品组做过测试,在select、update、delete操作下,聚集索引性能较高,在插入记录时,聚集索引和非聚集索引性能相同,没有出现聚集索引影响插入速度的现象,但在生产环境中,还是要谨慎行事。
原文链接:https://www.cnblogs.com/zxtceq/p/7920431.html